

|
FEATURE:
ICPR 2010 J.K. Aggarwal Prize Lecture |
|
Scene and Object Recognition in Context
By Antonio Torralba (USA) Reviewed by Oya Çeliktutan (Turkey)
|
|
In this talk, Prof. Torralba focused on visual context and its role on object recognition. He started his talk by giving an example of the most common object detection problem: face detection. The most successful approach today is to train a classifier with samples of faces and background. To detect faces in a given image, one extracts all possible overlapping patches at all spatial locations and scales, then for each patch one applies the classifier to decide whether the patch contains a face or not. This idea can be extended to multiclass object detection problems by training a separate binary classifier for different objects and for each viewpoint. This leads to the “Head in the coffee beans problem” in which we ask the detector to find the face among a collection of coffee beans in real time. As shown in Figure 1, there are many distracters and only one positive sample of our target. The detection problem is far from this example. Normally, scenes are more distracting; there are also many different classes of objects we want to detect; and the context relationship among them makes the detection process as hard as possible. However, the other objects in a scene can be used as an information source to help in the recognition and detection of objects.
Figure 1. Head in the coffee beans problem: can you find the head in this image?
In the real world, objects occur with other objects in a particular environment, e.g., a computer screen with keyboard, table, and chair in an office environment. The visual system exploits these contextual associations to localize and recognize objects efficiently. For example, Figure 2 verifies how amazing our visual system is. Despite the low resolution, one can guess what the objects in the image and the action of the person are.
Figure 2. Let’s verify how amazing the visual system is
For correct detection and recognition of objects, we need to train the classifiers with huge number of samples for each category. The most challenging issue is the lack of data. Prof. Torralba then continued his talk with the data collecting problem and introduced LabelMe, a database and a web-based tool for image annotation [1]. The web-based tool provides users with the ability to browse databases, query images and draw polygons. Thus, a large database of annotated images is built consisting of 530,000 polygons, 8,500 different object descriptions, and 265 object descriptions exhibiting more than 100 instances. Some example object categories that frequently occur in the database are shown in Figure 3. So now the question is, how do we use all this data for object recognition and scene understanding? One is the classical way: take a picture, train a bunch of detectors to recognize different objects that compose the image, and then infer the scene. There is also another way that one can analyze the image by a set of representations such as summary statistics, configuration of textures. There is therefore a lot of work to investigate how the human visual system understands the scene, based on objects or something more abstract. As a case in point, Prof. Torralba invoked a memory test, remarking that one aspect of visual recognition is that humans are able to recognize the meaning or gist of an image within 1/20 of a second and remember its global layout, though some objects and details can be forgotten. Psychologists have been studying these kinds of representations for computer vision to extract the general idea, geometry and main objects of an image, especially in the framework of fast scene representations. Prof. Torralba introduced dominant global texture descriptors, bag of words, non-localized textons, and spatially organized textures [2] which fit into this category.
Figure 3. Sample annotated images of LabelMe database
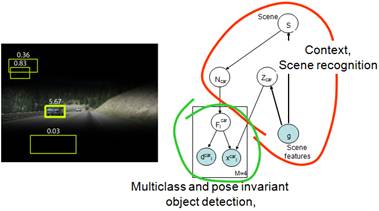
Prof. Torralba continued his talk by defining scene categorization task –given a picture, identify the place that it depicts. The largest available dataset of scene understanding contains only 15 classes. For this reason, the Scene Understanding (SUN) Dataset project is conducted to establish a database including all possible scene categories from Abbey to Zoo, resulting in 899 categories and 130,519 images [3]. Xiao et al. [3] performed scene categorizations using various computational features, which have no explicit object awareness. For each image, these features encode statistics of color, self similarity, geometric layout, and texture, and are used to train a classifier, such as SVM, in a one-against-all scheme. They measured human scene classification performance on the SUN database and compared the results with the features. In categorization results, generally, features that perform better are more likely to induce the same mistakes that humans make. The focus of the talk was to the integration of scene recognition with object recognition. Reasoning about the scene leads one to consider a subset of object categories and build more efficient object recognition systems. By combining a detector with a global context model, we also exploit the correlations between different object classes, i.e., location with respect to each other and the aspect of the objects in a scene. For example, the point of view of cars is correlated with the orientation of the street. But also, the location of the ground in the scene is correlated with the location of the objects in the scene. These scene cues can be used to determine the location of objects of interest as illustrated in Figure 4.
Figure 4. Integrated model of scenes, objects and parts
The integrated model is followed by the question: is context really needed? If we have a small number of classes, objects are clearly defined by their local appearance. But, when we have many object classes, it gets more complicated to detect objects efficiently. Moreover, context is important to figure out not only what the object is but also to define what an unexpected event is. An example is shown in Figure 5. On the left, the context changes the interpretation of the object—the car is only a toy that we cannot drive. On the right, a car in the swimming pool is an unexpected event.
Figure 5. Why context is important?
Prof. Torralba concluded his talk by presenting interesting results from the SUN database. He concluded that learning the object dependencies and using the tree-structured context models [4] can significantly improve the object recognition performance and also enable detection of images out of context.
[1] B. Russell, A. Torralba, K. Murphy, W. T. Freeman, LabelMe: a database and web-based tool for image annotation, International Journal of Computer Vision, pages 157-173, Volume 77, Numbers 1-3, May, 2008. [2] R. Datta, D. Joshi, J. Li, and J. Z. Wang, Image Retrieval: Ideas, Influences, and Trends of the New Age, ACM Computing Surveys, vol. 40, no. 2, pp. 5:1-60, 2008. [3] J. Xiao, J. Hays, K. Ehinger, A. Oliva, and A. Torralba, SUN Database: Large Scale Scene Recognition from Abbey to Zoo, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, June 2010. [4] M. J. Choi, J. Lim, A. Torralba, and A. S. Willsky, Exploiting Hierarchical Context on a Large Database of Object Categories, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, June 2010. |




|
Professor J.K. Aggarwal is widely recognized for his extensive contributions to the field of pattern recognition and for his participation in IAPR’s activities.
The J.K. Aggarwal Prize is a biennial award given to a young scientist who has brought a substantial contribution to a field that is relevant to the IAPR community and whose research work has had a major impact on the field.
This year’s recipient was Professor Antonio Torralba Computer Science and Artificial Intelligence Laboratory, Department of Electrical Engineering and Computer Science, MIT, USA |
