|
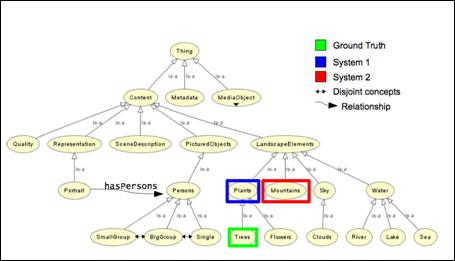
Abstract This text describes the ImageCLEF benchmark for multilingual, multimodal image annotation and retrieval. First, the general field of multimedia retrieval evaluation and the situation of ImageCLEF in this field are explained. Then, the ImageCLEF 2009 tasks, their objectives and the participation in these tasks are described. As of 2010, the format of CLEF (Cross Language Evaluation Forum) and ImageCLEF is changing; these changes are presented in detail to motivate readers of the IAPR Newsletter to participate in CLEF and ImageCLEF 2010. Introduction In the 1990s, evaluation was clearly not one of the strong points of the multimedia retrieval domain, but this has changed over the past ten years and benchmarking has become an important tool for advancing the field. The most well-known benchmark is clearly TREC (Text REtrieval Conference, trec.nist.gov/) for information retrieval and TRECVid (trecvid.nist.gov/) for multimedia (video) retrieval. CLEF (Cross Language Evaluation Forum, www.clef-campaign.org/) and its image retrieval part ImageCLEF (www.imageclef.org/) have also become very popular over the past years with 190 registered users for CLEF and over 90 for ImageCLEF in 2009. Other benchmarks in multimedia retrieval include ImageEVAL for several imaging tasks, SHREC (SHape REtrieval Contest) for the retrieval of 3D objects and MIREX (Music Information Retrieval EXperiment) for music retrieval. In the IAPR, there are also two technical committees dealing with evaluation issues on several levels (IAPR TC12 Multimedia and Visual Information Systems and IAPR TC5 Benchmarking & Software) ImageCLEF started with four participants in 2003 and a single photographic retrieval task and has since grown to over 90 participants in six different retrieval tasks. ImageCLEF was already described in the IAPR Newsletter in early 2006 [1] where the tasks of ImageCLEF 2005 were presented and the ideas for ImageCLEF 2006 were outlined. Since then, ImageCLEF has become a much larger forum, and the tasks have become more varied, have deployed larger image collections, and have also created more realistic tasks and topics. The goals have remained the same in promoting multilingual and particularly multimodal (mainly image combined with text) retrieval, making modern retrieval techniques comparable, and showing the improvement in the field. A secondary goal has always been to increase collection size but still retain a low entrance level to tasks, thus allowing research groups without large supercomputing centers to participate without problems. A large number of the ImageCLEF participants are actually PhD students. ImageCLEF 2009 With over 90 registrations, ImageCLEF set a new record in 2009 with 62 of these participants not only registering but also submitting results to at least one of the tasks. The ImageCLEF 2009 workshop hosted a large poster session for visual retrieval that fostered many lively discussions among the participants. With six tasks, there were also more tasks than ever before and this variety of tasks and collections led several participants to concentrate only on one or two of the available tasks. In the following subsections, the tasks are described in more detail. Photographic Image Retrieval In 2008 and 2009 the goal of the photographic retrieval task was to promote diversity in retrieval results; therefore, besides precision, the so-called cluster recall was also measured, where images regarded as relevant to a query were clustered into groups, each group representing a different aspect of the query topic, and retrieval systems had to represent a maximum number of these clusters in the first 20 results. In 2009, a new collection of about 500,000 images was made available to the participants by the Belga news agency. This in itself is a challenge for many image retrieval systems but also meant that a realistic size has been reached. (See [2]). Photographic Image Annotation The photographic annotation task, new for 2009, used a small ontology for the annotation of images containing a hierarchy of 53 topics. 5,000 images of a FlickR collection were distributed as training data and 13,000 as test data (Figure 1). (See [3]).
Figure 1: Part of the hierarchy of the ontology and their relations. Wikipedia Image Retrieval The Wikipedia image retrieval task distributed a collection of 150,000 images uploaded by Wikipedia users. The textual descriptions of the images in English were also distributed. Topics contained at least one image and a short query text. Topic generation, as well as the assessment for the creation of ground truth, were partly done collaboratively with the participants of the task. (See [4]). Robot Vision Task The robot vision task was also new in 2009. The goal of the task was to learn places where a robot had taken pictures and then re-identify the place later when the robot passed again. The challenges include changes in lighting and the placement of the furniture and small modifications, for example people being temporarily in the room (Figure 2). (See [5]).
Figure 2: Example images used for the robot vision task. Medical Image Retrieval In the medical image retrieval task, a larger database of images and texts of medical articles containing 85,000 images were made available to participants. Textual techniques clearly outperformed visual techniques. A new task of case-based retrieval was introduced with 5 example topics. In this task, a medical case including anamnesis, clinical data, images and a description of problems but no diagnosis were given to participants who had to find articles in the literature dealing with similar cases. The goal of this task was to bring the retrieval of medical images closer to clinical routine. (See [6]). Medical Image Annotation In the medical image annotation task, the classes and evaluation measures of the past four years of the task were distributed to participants along with new test data. Groups were then expected to score the data of each year, also to show improvements compared to the earlier years of the medical image annotation task. (See [7]). A second medical image annotation task focused on the detection and classification of lung nodules from 3D data sets in the medical DICOM format (Digital Imaging and Communication in Medicine). This task is detailed in [6]. CLEF 2010 an d ImageCLEF 2010 For the past ten years, CLEF has been organized as a workshop at the European Conference on Digital Libraries (ECDL). As CLEF has grown in size (with over 250 participants), the decision was made to establish CLEF as an independent entity with a clear conference structure that would give more room for the tasks presented and that would give researchers the possibility to present scientific work. The next CLEF conference will thus be held over four days in Padova in 2010 (www.clef2010.org/). Two days will be dedicated to scientific discussions around evaluation in information retrieval with a focus on multilingual and multimedia issues. Two days will then be dedicated to labs, meaning the former CLEF evaluation tasks. This new structure also has an influence on ImageCLEF: fewer tasks and increased aspects of multilinguality and language-independence. The Wikipedia retrieval task will be made multilingual by adding descriptions in several languages. It will also become larger by crawling a new collection of Wikipedia images and have a stronger focus on imaging data and visual queries. The image annotation task will again be held using a FlickR database with the 2009 data to be used as training data for the task. The robot vision task will require detection of objects in the robot images as well, which links this task closer to the photo annotation task. Finding the place of a picture will still remain one of the goals of the task. For the medical retrieval task, it is again planned to increase the size of the collection distributed to the participants, potentially including a larger number of different journals as well. Another major goal is to move the topics closer to clinical routine by having more case-based topics, i.e., topics where a medical case with several images is given without diagnosis and where articles treating similar cases need to found from the literature using text and visual information. Conclusions ImageCLEF has become a popular platform for image retrieval evaluation that gives researchers the opportunity to discuss their techniques and compare performance on the same data sets and in the exact same framework. With the change of the CLEF format in 2010, we hope to create an even larger forum on visual information retrieval evaluation. We hope that this article will motivate researchers to participate in the benchmark so as to bring together as many state-of-art techniques in the field as possible and compare their performance on the same data and the same tasks in order to advance visual information retrieval. |

|
Feature |


|
By Henning Müller (Switzerland) and Theodora Tsikrika (The Netherlands) |


|
Other articles in the Global Pattern Recognition Series:
Fraunhofer IGD
India’s Center for Soft Computing Research
German Research Center for Artificial Intelligence
China’s Laboratory of Pattern Recognition
Pattern Recognition in Two National Laboratories |

|
Contact the authors:
Henning Müller
Theodora Tsikrika |
|
References: [1] Henning Müller, Paul Clough, The ImageCLEF Benchmark on Multimodal, Multilingual Visual Images, IAPR newsletter volume 28 number 2, April 2006.
[2] Monica Lestari Paramita, Mark Sanderson, Paul Clough, Diversity in Photo Retrieval: Overview of the ImageCLEFPhoto Task 2009, CLEF 2009 working notes, Corfu, Greece, 2009.
[3] Stefanie Nowak, Peter Dunker, Overview of the CLEF 2009 Large Scale - Visual Concenpt Detection and Annotation Task, CLEF 2009 working notes, Corfu, Greece, 2009.
[4] Theodora Tsikrika, Jana Kludas, Overview of the WikipediaMM Task at ImageCLEF 2009, CLEF 2009 working notes, Corfu, Greece, 2009.
[5] Barbara Caputo, Andrzej Pronobis, Patric Jensfelt, Overview of the CLEF 2009 Robot Vision Track, CLEF 2009 working notes, Corfu, Greece, 2009.
[6] Henning Müller, Jayashree Kalpathy–Cramer, Ivan Eggel, Steven Bedrick, Saïd Radhouani, Brian Bakke, Charles E. Kahn Jr., William Hersh, Overview of the CLEF 2009 Medical Image Retrieval Track, CLEF 2009 working notes, Corfu, Greece, 2009.
[7] Tatiana Tommasi, Barbara Caputo, Petra Welter, Mark Oliver Güld and Thomas M. Deserno, Overview of the CLEF 2009 Medical Image Annotation Track, CLEF 2009 working notes, Corfu, Greece, 2009. |
|
NOTE: Registration for ImageCLEF 2010 is possible from the registration website medgift.unige.ch:8080/CLEF2010/ It is also possible to submit scientific papers on evaluation topics to the main CLEF2010 conference clef2010.org/ |